Circuit Breaker
データ送信処理が失敗した場合に、リトライの間隔を指数関数的に伸ばしていくことで最終的に処理を完結させるためのアルゴリズムとしてExponential Backoffというものがある。AWSのSDKなどで実際に触ったことがある人も多いと思うけど、実装が単純でそれなりに大規模な環境でも効果的に動く。ジッターなどは抜きに簡易化して書くと次の様な感じでしょうか。
MAX_RETRIES = 10
retries = 0
begin
// 何かの処理
rescue => e
if retries < MAX_RETRIES
retries += 1
sleep 2 ** i
retry
else
raise
end
end
只、リトライを実行しているの間処理をブロックしても構わない場合や、並列度にある程度の上限がある場合(CLIのツールとか1処理に実行するAPIコール数が決まってる場合とか)はこれでも問題ないんだけど、ブロックするのは困る場合などにはリトライせず直ぐにエラーを返して貰いたいケースがある。
というか今作ってるsocketにデータを書くライブラリで、一定数処理が失敗したらしばらくの間直ぐにエラーを返してほしくて、且つその間隔が指数関数的に伸びていくような物がほしいなと思う事があって、有りがちなケースだしパターン化されてないかなと思ったけどよくよく考えたらCircuit Breakerをそのまま使えそうとおもったらいい感じだった。
Circuit Breakerとは
私がCircuit Breakerを初めて見かけたのはNetfrixのHystrixというライブラリについて調べていた時だったと思う。
その後、Martin Fowler先生の記事と、そこで紹介されてたRelease It!という本で詳細を知ったんだけど、初出がどこかはちょっとわからない。
https://martinfowler.com/bliki/CircuitBreaker.html
Release-本番用ソフトウェア製品の設計とデプロイのために-Michael-T-Nygard
どちらかと言うとマイクロサービスのコンテキストで語られることが多くて、複数サービス間で構築されたシステムにおいて、あるシステムに障害が発生した場合に名前の通りそのシステムを遮断して全体影響を抑える様な役割と、実行結果の成功や失敗のイベントを一箇所で管理して検知しやすくするための役割がある。Exponential Backoff などのように処理を再試行するための物ではなく、処理を実行させないようにするところに大きな違いがある。
例えば、Webリクエストの処理内で外部の依存しているAPIをネットワーク経由で呼び出す場合に、ある1つの依存先サービスが疎通不能になった場合にリトライやタイムアウトするまで処理が遅延してしまい、連鎖的にシステム全体がダウンしてしまう事は極力避けたい。
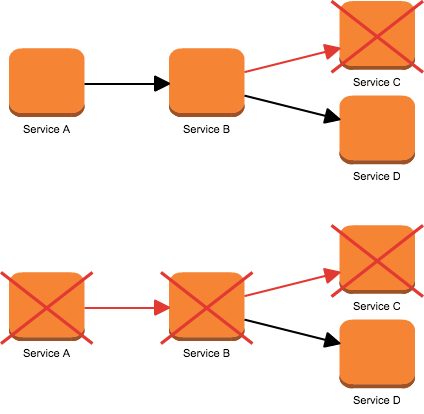
そこで、各サービスへの通信クライアントの処理をCircuit Breakerを経由するようにして、閾値以上失敗が続いた場合には処理を実行せず、直ぐにエラーを返してサービスを一定期間遮断する。
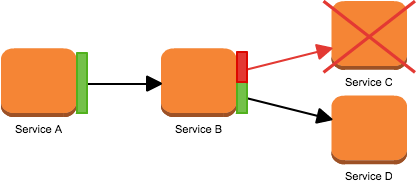
遮断に関しては、例えば表示が少しおかしくなるのを許容するとかであれば、依存先のサービス失敗時の初期値やFallback方法を決めるなりすればいい。遮断すると維持出来ないサービスでも、Circuit Breakerには最初の図のように、システム全体がブロックすることによる過負荷を避ける目的もあるので、それなりにどういったシステムでも効果は出るように思う。
APIの呼び出し以外にも、こういった問題は本当によくあって(例えばDBへのクエリとか)、Release It! の中でも結構同じような内容の話が安定性のアンチパターンとして書かれているので興味がある人は是非読んでみると良いと思う。
状態遷移とイベント監視
Circuit Breaker自体は結構単純で、内部に3つの状態を持った有限オートマトンである。
- Closed
- 通常時はこの状態、処理は普通に実行される
- 処理が失敗した場合、エラー(数|率)が閾値を超えない場合Closed状態のまま
- 処理が失敗した場合、エラー(数|率)が閾値を超えた場合Open状態に移行する
- Open
- 全ての処理は実行されず即時エラーを返す
- 一定時間経過後、Half Open状態に移行する
- Half Open
- 処理が成功した場合、Closed状態に移行する
- 処理が失敗した場合、Open状態に移行する
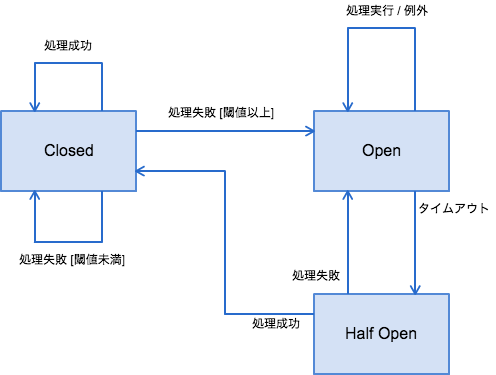
マイクロサービスの例で言うと、設定閾値以上のエラーレスポンスを受け取る或いはタイムアウトになるとOpen状態に遷移する。閾値はクライアント実装と設定次第で連続エラー数だったり直近の割合だったりする。
Open状態で実行された処理は全て実行されずにエラーが返る。OpenからHalf Openには一定時間後に移行するが、Half Open状態での処理に失敗すると再度Open状態に移行する。その際に指数関数的に待機間隔が増えていく実装が多い。Half Open自体は使う側が意識することは殆どなく、どちらかというと待機時間の制御の為のステータスと言える。
処理結果に合わせて内部でこれらの状態に遷移しており、状態が変わったときに外部に通知する手段を持つ。どういうインターフェースで通知を受け取れるかは実装次第だが、例えばGoの実装である rubyist/circuitbreaker では、Goらしくchannelでイベントを受け取れるようになっている。
// Creates a circuit breaker that will trip if the function fails 10 times
cb := circuit.NewThresholdBreaker(10)
events := cb.Subscribe()
go func() {
for {
e := <-events
// Monitor breaker events like BreakerTripped, BreakerReset, BreakerFail, BreakerReady
}
}()
cb.Call(func() error {
// This is where you'll do some remote call
// If it fails, return an error
}, 0)
こうやって、一箇所で状態を監視できるようになることがもう一つのメリットで、例えばHystrixなんかでは専用のDashboardが用意されていたりもする。
おわり
マイクロサービスの例で色々と紹介してきたが、基本的には通信を伴う処理全般で使用することが出来る。今書いているライブラリはGoのgo routineベースのfluent-loggerで、fluentdへのコネクションにwriteする部分で使っている。
https://github.com/daichirata/fluent-logger-go/blob/master/logger.go#L148
待機期間が存在するため応答性とのトレードオフが多少あるけど、Circuit Breakerが起動するのはそもそも障害なりで接続が出来なくなっている状態なので問題ないケースも多いかなと思う。